Hi there,
I recently focused on playing around with ant colony AI (artificial intelligence) methods, as part of my second semester undergraduation project in Software Engineering.
Wikipedia's definition for Ant Colony Optimization is the following:
In computer science and operations research, the ant colony optimization algorithm (ACO) is a probabilistic technique for solving computational problems which can be reduced to finding good paths through graphs.Unlike previous posts, it is a multithreaded solution which runs best on a single machine and not in a cluster and this post is about TSP (Traveling Salesman Problem) and not about finding shortest paths in a graph.
The Input
At first, we have to decide which input we take. In my case, this task was a university assignment so I have to use the given one. It is the Berlin52 problem which should be solved with the less costly route along the 52 best known / famous places in Berlin.
You can download an euclidian 2D coordinate version of it here. Just look for the "berlin52.tsp.gz" file. There is also an already calculated optimal solution here.
Plotting the file is going to show a cool roundtrip:
 |
| GnuPlot of the Berlin 52 Tour |
The file content looks quite like this:
1 565.0 575.0On the leftmost side is the ID of the vertex, in the middle is the x-coordinate and on the rightmost side is the y-coordinate in the euclidian plane.
2 25.0 185.0
3 345.0 750.0
4 945.0 685.0
The Algorithm
This algorithm is a mimicry of the real-life behaviour of ants. As you might know, Ants are quite smart in finding their way between their colony and their food source. A lot of workers are walking through the proximate environment and if they find some food, they leave a pheromone trail.
Some of the other ants are still searching for other paths, but the most of them are following the pheromone trail- making this path even more attractive. But over time the pherome trail is starting to decay / evaporate, so it is losing its attractiveness. Due to the time component, a long way has a very low density of the pheromone, because the pherome trail along the longer path is evaporating faster. Thus a very short path has a higher density of pheromones and is more attractive to the workers converging onto an approximately optimal path for our TSP problem.
For the problem, we are dropping ants on random vertices in our graph. Each ant is going to evaluate the next best destination vertex based on this following formula:
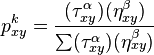 |
| Wikipedia.org |
The variable "Tau" is the amount of pheromone deposited on the edge between "xy". It gets raised by "alpha" which is a heuristic parameter describing how greedy the algorithm is in finding its path across the graph. This is going to be multiplied by our apriori knowledge of how "good" the edge is. In our case this is the inverted distance (1 / distance) between x and y. This gets raised by "beta" which is also a heuristic parameter, which describes how fast the ants are going to converge to a steady solution. To get a transition probability to a vertex, each gets divided by the sum of the numerator over all possible left destination vertices.
The next equation is about adjusting the pheromone matrix, which is described by the following formula:
"Tau" is the amount of absolute pheromone which gets deposited for worker "k" on the "xy" edge. "Rho" is a factor between 0-1 which represents the decay of the pheromone. This gets multiplied by the current amount of pheromone deposited and we just add updated new pheromone to it (which is the delta "Tau"). Delta "Tau" is an equatation too:
Wikipedia.org

| Wikipedia.org |
Finish! That is all we need to start the implementation!
The whole thing works like this:
- Initialize the best distance to infinity
- Choose a random vertex in the graph where to plant your ant
- Let the ant work their best paths using the formulas from above
- Let the ant update the pheromones on our graph
- If the worker returned with a new best distance update our currently best distance
- Start from 2. until we found our best path or we have reached our maximum amount of workers.
- Output the best distance
So let's see how we can multithread this.
How to Multithread
In this case, multithreading is very easy. Each worker unit (in my repository called "Agent") is a single thread. In Java we have a cool thread pool construct called ExecutorService and a completion service which tells us when workers finished.
We are submitting a few workers for to the pool, they work on the same resources and once completed we get a reponse of the completion service.
Woot? Shared resources? Yes we need some sort of synchronization. In our case when writing to the pheromone matrix. In my latest implementation I used lock-free updates using Guava's AtomicDouble.
The whole algorithm is not going to change, we are just working in parallel.
The Result
After a lot of parameter testing you can find a very good solution:
 |
| Console output of my algorithm, finding a very close solution to the optimal distance for Berlin52 |
Parameter Testing
Because there are a hell lot of parameters (5) in there, we have to write an testing utility which calculates the best parameters for our problem (aka GridSearch).
We only care about the distance to the optimal solution:
In the grid search we only want to keep the lowest possible mean distance to the optimal solution (measured over multiple repetitions) and a very low variance.
For Berlin52, the best parameters using 200k agents I found are:
Alpha = 0.1
Beta = 9
Q = 1e-4
P = 0.8
So feel free to check out the code in the repository and let it run.
And please feel free to use this as a hint for your own implementation, or even improve it via a pull request.
Thanks for your interest and have fun :-)
Bye!
Repository https://github.com/thomasjungblut/antcolonyopt
