This is a small follow-up post to the similarity aggregation (short SEISA, set expansion by iterative similarity aggregation) post before, it is just a small idea about creating a graph from data collected by this algorithm. So don't expect the master plan how to create a semantic graph from your data, it is just some brainstorming post.
I was very much into semantic relations in the last few months and I think the best way to express them is a graph.
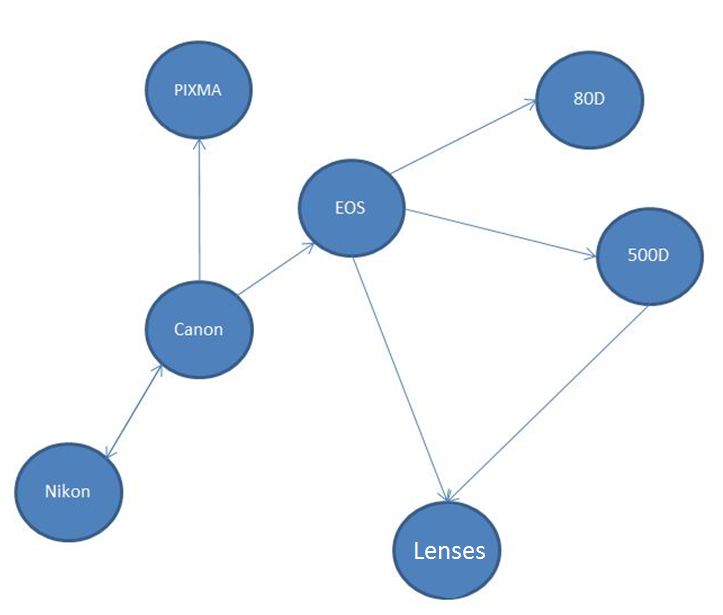 |
| Semantic graph arround Canon |
You may be reminded of the Knowledge Graph by Google, yes it actually was inspired by it. However it is much more computationally heavy to use it (and even build it) than you might think of it first.
In any case, an algorithm that builds this can be seeded from the SEISA algorithm. Think of a generic starting point that starts in wikipedia and reads the facts about Carl Friedrich Gauss, keywords like "mathematician" will yield to other mathematicians very fast.
Google is (MAYBE) mainly using the semantic annotations to create a relation between the nodes, which is mainly depth first search (because you get a lot of information through Gauß). Whereas the SEISA information could yield to more breadth results like other mathematicians in his century like Riemann or Poincaré.
Creating this semantic graph for (at least) products, brands and other product related features will be my personal ambition for the next few years. Of course Google aims at the most generic way, they have the computational resources to do it for all the web.
Another problem they have is actually how to cut off information to be valuable to the user. Not everybody searching for "Gauß" is interested in his whole life story or other mathematicians, but maybe more into the algorithm for solving equations.
Also understanding queries and parsing the graph accordingly is another interesting new research field.
For example in the above graph arround Canon, what if a user wants to know about other brands LIKE Canon (SQL like for example: SELECT brands LIKE "Canon"). In this case, an engine would traverse the graph breadth first search starting by Canon to find nodes with the attribute "Brand". It would find their brand PIXMA and EOS. Distance is also a very important topic in this relation, how far are the relevant nodes away from their starting point?
Frameworks building such a graph is currently a very important aspect. There are a few helpful ones:
- Graph databases, e.G. Titan https://github.com/thinkaurelius/titan
- Graph only focused processing engines, e.G. Giraph http://giraph.apache.org/
- Of course Hama, to use sophisticated machine learning or mathematical algorithms that can't be expressed as a graph http://hama.apache.org/
- Good old Hadoop MapReduce is of course a help for various data crunchings as well.
Beeing part of that, is one of the things I most enjoy.
We will see how far Google integrates the graph into their search, it will be a driving factor if they manage to query a large scale graph successfully and within milliseconds.
This comment has been removed by a blog administrator.
ReplyDelete